
[Paper Review] Semantic Uncertainty: Linguistic Invariances For Uncertainty Estimation in Natural Language Generation (ICLR 2023)
Published:
Semantic Uncertainty로 불확실성 측정하기
Abstract
Question answering (QA) 와 같은 태스크에서는 foundation model의 출력이 신뢰할 수 있는 지가 중요하다. 하지만 자연어에서는 다른 문장이라도 같은 뜻을 가질 수 있기 때문에 uncertainty를 측정하는 것은 어렵다. 따라서, 해당 논문에서는 같은 의미를 가지는 언어의 엔트로피를 통합하는 semantic entropy를 제안한다. 해당 방법은 단일 모델로 수정 없이 unsupervised 방식으로 동작한다.
Introduction
Natural language generation (NLG)에서 foundation model의 uncertainty에 대한 연구를 많이 탐구되지 않았다. 기존의 연구에 따르면 안전한 AI 시스템 개발에 uncertainty 측정이 중요한 요소이다. 하지만, 다른 딥러닝 어플리케이션과 다르게 자유로운 형식의 NLG는 uncertainty 측정이 어렵다. Foundation model은 token-likelihood를 출력하기에 어휘적 자신감(lexical confidence)를 평가할 수 있다. 하지만, 우리는 어휘보다 의미가 중요하다. 가령 “France’s capital is Paris” 혹은 “Paris is France’s capital” 중 어떤 문장을 생성할 지 불확실하다면, 사실 두 문장이 같은 의미를 가지기에 불확실한 것이 아니다. 따라서, 해당 논문에서는 기존의 sequence-likelihood를 측정하지 않고 텍스트의 의미적 확률을 내포하는 semantic likehood를 측정하고자 한다.
Semantic likelihood를 측정하기위해 만약 두 문장이 서로를 유추할 수 있다면 같은 의미로 클러스터링하는 알고리즘을 제안하고 측정한 semantic likelihood를 통해 semantic uncertainty를 측정한다. 추가적으로, 해당 논문에서는 sampling을 할 때, 다양성과 정확도의 trade-off에 대해서 분석한다.
Challenge in Uncertainty Estimation for NLG
기존의 NLG uncertainty는 black-box로 language model을 통해 정답 여부를 확인하여 측정하거나 entropy를 계산하여 확률적 모델을 사용하여 측정하였다. 엔트로피가 다음과 같이 계산한다고 할 때,
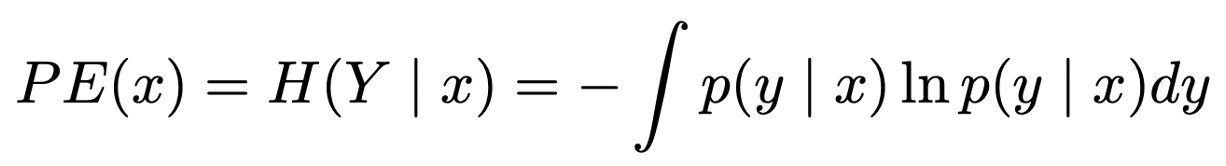
NLG에서 문장 전체의 확률은 이전 토큰을 기반으로한 새로운 토큰 생성의 조건부 확률을 사용하여 엔트로피를 계산한다.
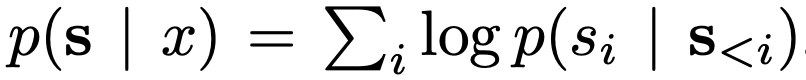
$s_{i}$은 $i$번째 생성 토큰이며, $s_{}$는 이전에 생성된 토큰들을 의미한다. 혹은 다음과 같이 geometric mean log-probability를 이용하기도 한다.
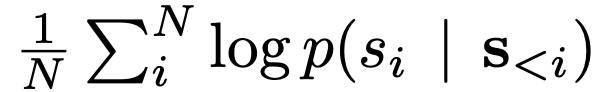
하지만 다른 머신러닝 모델들과 다르게 텍스트 생성 분야는 출력이 상호 배타적이지 않고, 생성한 어휘가 다르더라도 동일한 의미를 가질 수 있다. 따라서, 해당 논문에서는 문장의 의미가 같은 경우 semantic equilvalence classes $C$로 설정하여 같은 class의 두 문장은 동일한 의미를 가진다고 설정한다. 따라서, 기존에는 아래처럼 standard event-space $S$의 output을 보았다면
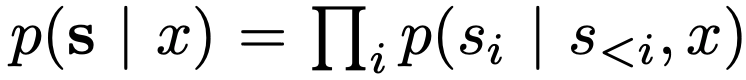
이제는 event-space를 $C$로 한정하여 확률을 계산한다.
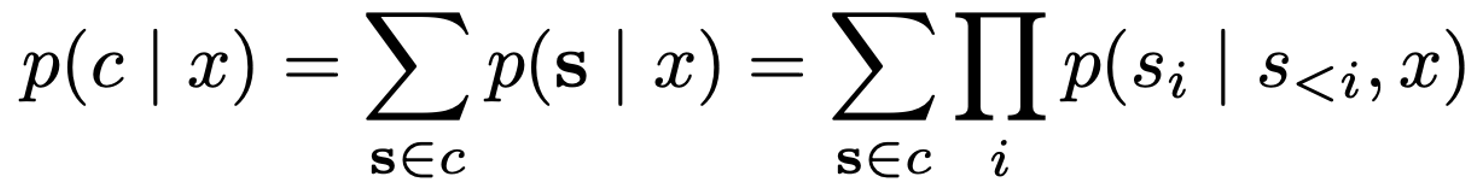
엔트로피를 계산하기위해 output-space의 기댓값이 필요한데, 자연어의 output-space의 경우 $O(T^{N})$ 차원이 필요하다($T$는 vocabulary의 크기, N은 토큰의 수를 의미한다). 또한 각 문장 별 정규화된 probability density function을 구할 수 없기 때문에 Monte Carlo integration을 통해 추정한다.
기존의 연구들에 따르면, 자연어의 문장이 길이가 길수록 낮은 joint likelihood를 가지기 때문에 긴 문장은 높은 엔트로피를 갖는다. 따라서, 해당 논문에서는 length-normalising 후에 엔트로피를 계산하는 방법을 제안한다.
Semantic Uncertainty
해당 논문에서는 semantic entropy를 계산하기 위해 semantic equivalence를 측정하는 알고리즘과 uncertainty 측정 알고리즘을 제안한다. 해당 방법은 다음과 같다.
- 주어진 문맥 x를 기반으로 LLM으로부터 M개의 문장을 샘플링한다.
- 같은 의미를 같는 문장을 bi-directional entailment 알고리즘을 통해 군집화한다.
- 같은 의미를 갖는 문장들의 확률을 더함으로써 semantic entropy를 계산한다.
1. Generating a set of answers from the model
먼저 하나의 모델로부터 M개의 문장을 sampling한다. Sampling의 경우 multinomial sampling 혹은 multinomial beam sampling을 사용하는데, sampling temperature와 sampling 방법이 성능에 큰 영향을 끼친다.
2. Clustering by semantic equivalence
Equivalence class $c$는 서로가 같은 의미를 가지는 문장들의 set을 의미한다. 문장들의 의미를 비교하기 위해서 해당 논문에서는 bidirectional entailment를 통해 operation $E$를 계산한다. 만약 두 문장이 같다면, 서로가 서로를 충분이 함의할 수 있을 것이라는 가정에서 시작한다. 해당 논문에서는 Deberta-large 모델을 MNLI에 학습한 모델을 통해 NLI를 계산한다. 두 문장이 같을 경우 equivalent를 사용하는데, 두 문장이 각각의 방향에서 모두 entailment일 경우에만 해당한다.
Bidirectional equivalence 알고리즘은 M개의 샘플 중에 2개를 뽑아 비교를 해야하기 때문에 최악의 경우 (M, 2)를 계산해야한다. 하지만 실제 상황에서는 M < 20 일 때 충분히 동작했고, Deberta-large 모델이 크기가 굉장히 작기 때문에 계산 속도가 굉장히 빠르다. 따라서, bidirectional entailment 알고리즘의 computational cost가 높지 않다.
3. Computing the semantic entropy
같은 의미를 가지는 문장들을 클러스터링하고, 클러스터 내 likelihood를 더함으로써 문장 별 엔트로피를 구하는 것이 아니라 의미 별 엔트로피를 계산한다.
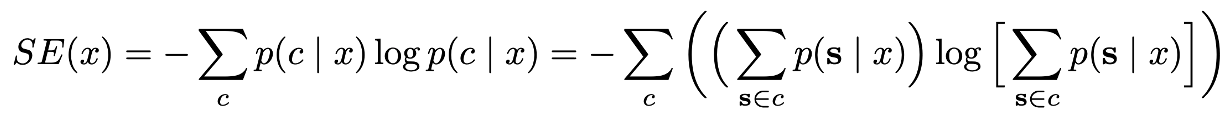
모든 meaning-class $c$에 대해 접근할 수 없기 때문에, 모델이 생성한 문장들에서 $c$를 샘플링하여 Monte Carlo integration을 사용하여 엔트로피를 계산한다. 추가적으로 length-normalisation을 사용하는 경우도 있다.
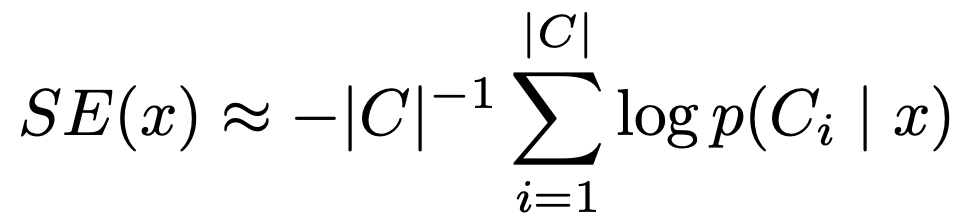
Evaluation
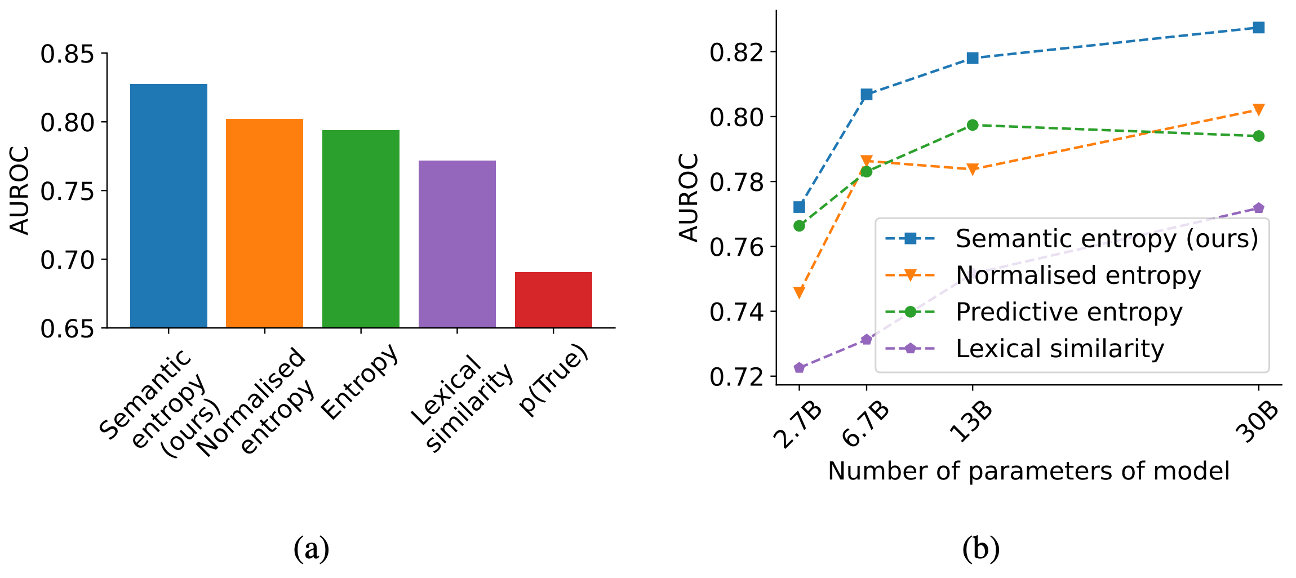
결과적으로 semantic entropy는 질문에 대한 모델이 정답인지 여부를 예측하는 실험에서 좋은 성능을 보인다. 위의 figure의 (a)는 TriviaQA에서의 결과로, semantic entropy가 다른 uncertainty 측정 모델들인 sequence entropy, lexical similarity, p(True)보다 뛰어난 성능을 보인다. 또한 (b)를 보면, semantic entropy의 경우 모델의 크기가 커질수록 점진적으로 uncertainty 예측 성능 또한 좋아지는 것을 볼 수 있다.
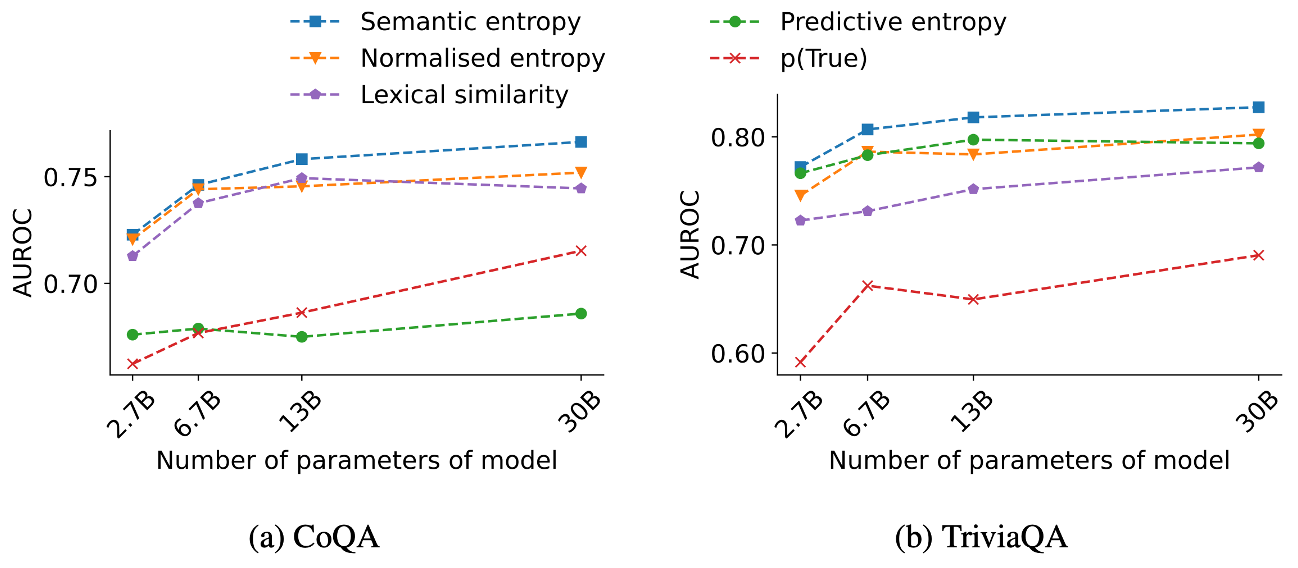
위의 figure (a)를 보면, CoQA 데이터 셋에서도 모델의 크기가 커질수록 semantic entropy의 성능이 다른 모델들에 비해 확연하게 좋아지는 것을 볼 수 있다. 또한 TriviaQA의 경우 ground truth가 한 단어이거나, 매우 짧은 구절이라면, CoQA의 경우 ground truth가 긴 구절과 짧은 구절을 모두 포함하고 있기 때문에 (a), (b)를 비교해보면, CoQA에서 length-normalisation의 효과가 뚜렷하게 나타난다.

위의 테이블에 따르면, 30B 모델에서 나온 출력의 clustering 결과 정답으로 응답한 클러스터 개수가 오답으로 응답한 클러스터의 개수보다 적다. 이를 통해 모델이 확신없이 대답하면 부정확한 대답일 확률이 높다는 것을 보여준다 (모델은 한 질문 당 10개의 답변을 한다). 또한 semantically distinct한 응답의 개수를 통해 uncertainty 측정을 하였다. 그 결과, semantic entropy는 distinct 답변의 개수보다 높은 AUROC 점수를 보였으며, 특히 CoQA처럼 어려운 태스크에서 더 좋은 성능을 보인다.
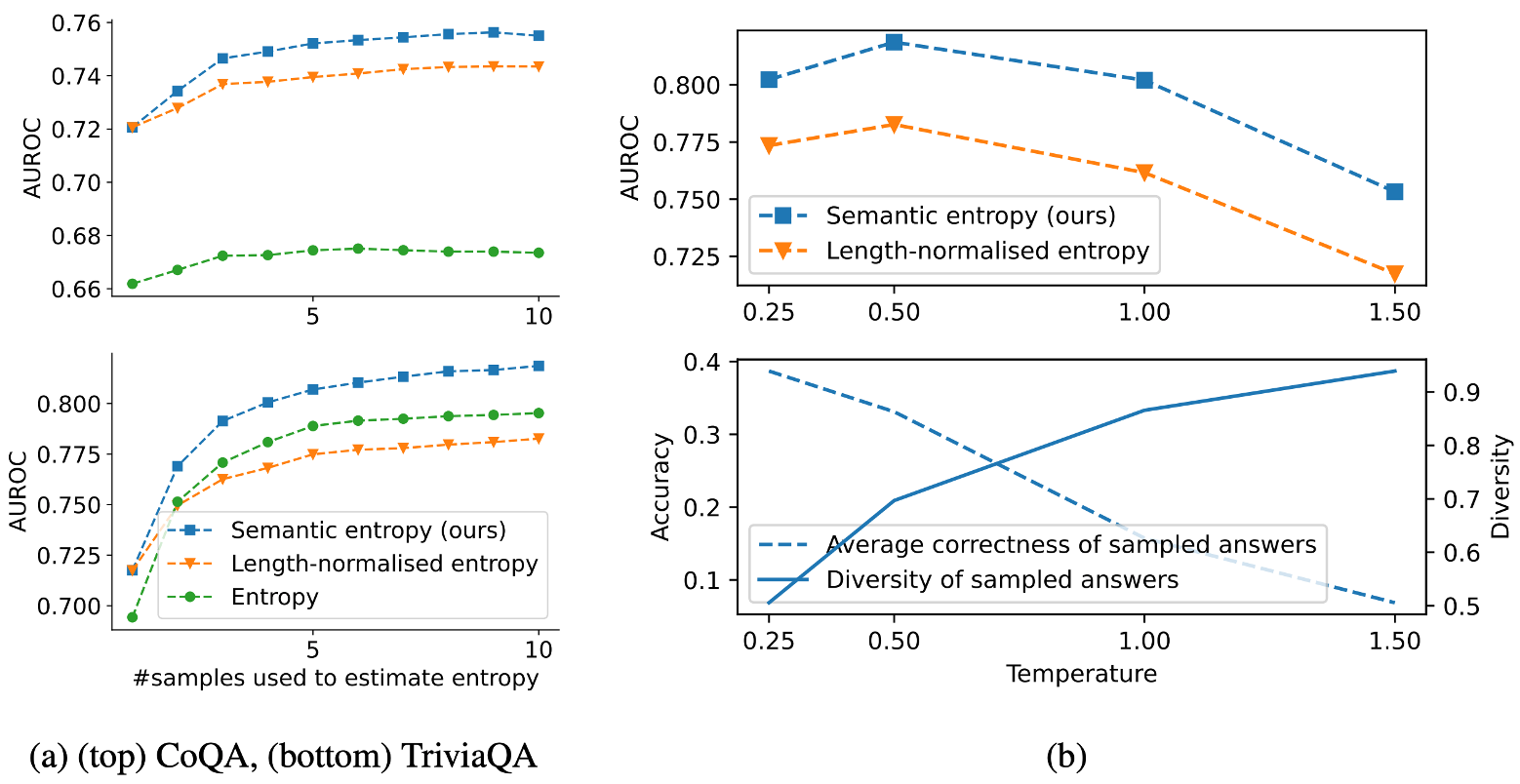
(a)에서 sample의 개수가 엔트로피에 미치는 영향을 보여준다. Sample의 개수가 많아질수록 점진적으로 성능이 증가하며, length-normalisation의 효과도 증가하는 것을 볼 수 있다.
또한 temperature가 미치는 영향을 분석하였다. Multinomial sampling에서 temperature를 증가시키면 sample의 다양성이 증가한다. Diversity의 경우 샘플된 문장들 중 가장 긴 문장과의 (1-ROUGE-L) 점수를 측정하였다. (b)에 따르면, temperature가 작을수록 응답의 correctness가 증가하였다. 따라서, 실험 결과 temperature를 중간 점수인 0.5로 하였을 때 가장 높은 AUROC 점수를 보였다. 이를 통해, 낮은 temperature는 정확도를 올리고, 높은 temperature는 다양성을 올리는 것을 볼 수 있다.
Conclusion
해당 논문에서는 semantic entropy라는 개념을 제시하여, LLM의 uncertainty를 측정한다. NLG 태스크는 다른 태스크들과 다르게 다른 응답이라도 정확히 같은 의미를 내포할 수 있기에 의미있는 결과를 보여준다. 같은 의미를 내포하는 지에 대해 평가하기 위해 sampling간의 bidirectional entailment 방법을 제안한다. 방법은 간단하지만 효과적으로 동작하기에 좋은 방법인 것 같다. 다만, figure가 해석하기 불편하기에 아쉬웠다.